P4D1: Understanding the Pavlov in Machine Learning
AI is able to learn ‘rules’ from highly repetitive data.
The single most important thing for AI to accomplish in the next ten years is to free us from the burden of repetitive work. Sebastian Thrun
You might enjoy the Machine Learning: Living in the Age of AI : A WIRED Film.
Understanding Machine Learning (Classification)
As we review A visual introduction to machine learning, be prepared to address the following questions;
- What is the difference between a feature and a target?
- What does it mean to classify?
- What does it mean to create a machine learning model?
- What does it mean to find ‘boundaries’ in our variables or features?
- How does finding ‘boundaries’ help us in ML?
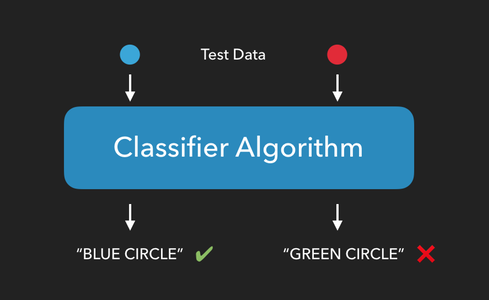
- What are false positives?
- What are false negatives?
- What is accuracy?
- What is training data?
- What is test data?
Machine learning identifies patterns using statistical learning and computers by unearthing boundaries in data sets. You can use it to make predictions.
One method for making predictions is called a decision trees, which uses a series of if-then statements to identify boundaries and define patterns in the data.
Overfitting happens when some boundaries are based on distinctions that don’t make a difference. You can see if a model overfits by having test data flow through the model.
As we review Model Tuning and the Bias-Variance Tradeoff, be prepared to address the following questions;
- What is bias?
- What is variance?
- What does the ‘minimum node size’ impact?
The bias error is an error from erroneous assumptions in the learning algorithm. High bias can cause an algorithm to miss the relevant relations between features and target outputs (underfitting).
The variance is an error from sensitivity to small fluctuations in the training set. High variance may result from an algorithm modeling the random noise in the training data (overfitting).
Models approximate real-life situations using limited data.
In doing so, errors can arise due to assumptions that are overly simple (bias) or overly complex (variance).
Building models is about making sure there’s a balance between the two.
As we review Tensorflow’s Neural Network playground, be prepared to address the following questions;
- What do the FEATURES represent?
- Can we tackle Google’s questions?
Reviewing the reward/penalty in Machine Learning
What is the ‘Pavlovian bell’ in the machine learning model?
ML Newbie mistakes
- If your model is near perfect in predicting, then you are probably cheating (at least for early stage and most problems).
- Watch out for transactional data
- Forgetting the importance of feature engineering.
- Not simplifying and explaining the model.
Packages for ML in Python
scikit-learn is the Python package for machine learning.
Install the one package to rule them all
import sys
!{sys.executable} -m pip install scikit-learn
- The Mac M1 chips have some issues. See the latest info on the Github issue.
- scikit-learn’s details
Should I import scikit-learn?
scikit-learn is very large, with many submodules. To help the user of your .py script understand your code, the consensus is to use from .... import .....


from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn.naive_bayes import GaussianNB
from sklearn import metrics